
Qualitative visualization of planning results.
Autonomous driving requires generating safe and reliable trajectories from complex multimodal inputs. Traditional modular pipelines separate perception, prediction, and planning, while recent end-to-end (E2E) systems learn them jointly. Vision–language models (VLMs) further enrich this paradigm by introducing cross-modal priors and commonsense reasoning, yet current VLM-based planners face three key challenges: (i) a mismatch between discrete text reasoning and continuous control, (ii) high latency from autoregressive chain-of-thought decoding, and (iii) inefficient or non-causal planners that limit real-time deployment. We propose ColaVLA, a unified vision–language–action framework that transfers reasoning from text to a unified latent space and couples it with a hierarchical, parallel trajectory decoder. The Cognitive Latent Reasoner compresses scene understanding into compact, decision-oriented meta-action embeddings through ego-adaptive selection and only two VLM forward passes. The Hierarchical Parallel Planner then generates multi-scale, causality-consistent trajectories in a single forward pass. Together, these components preserve the generalization and interpretability of VLMs while enabling efficient, accurate and safe trajectory generation. Experiments on the nuScenes benchmark show that ColaVLA achieves state-of-the-art performance in both open-loop and closed-loop settings with favorable efficiency and robustness.
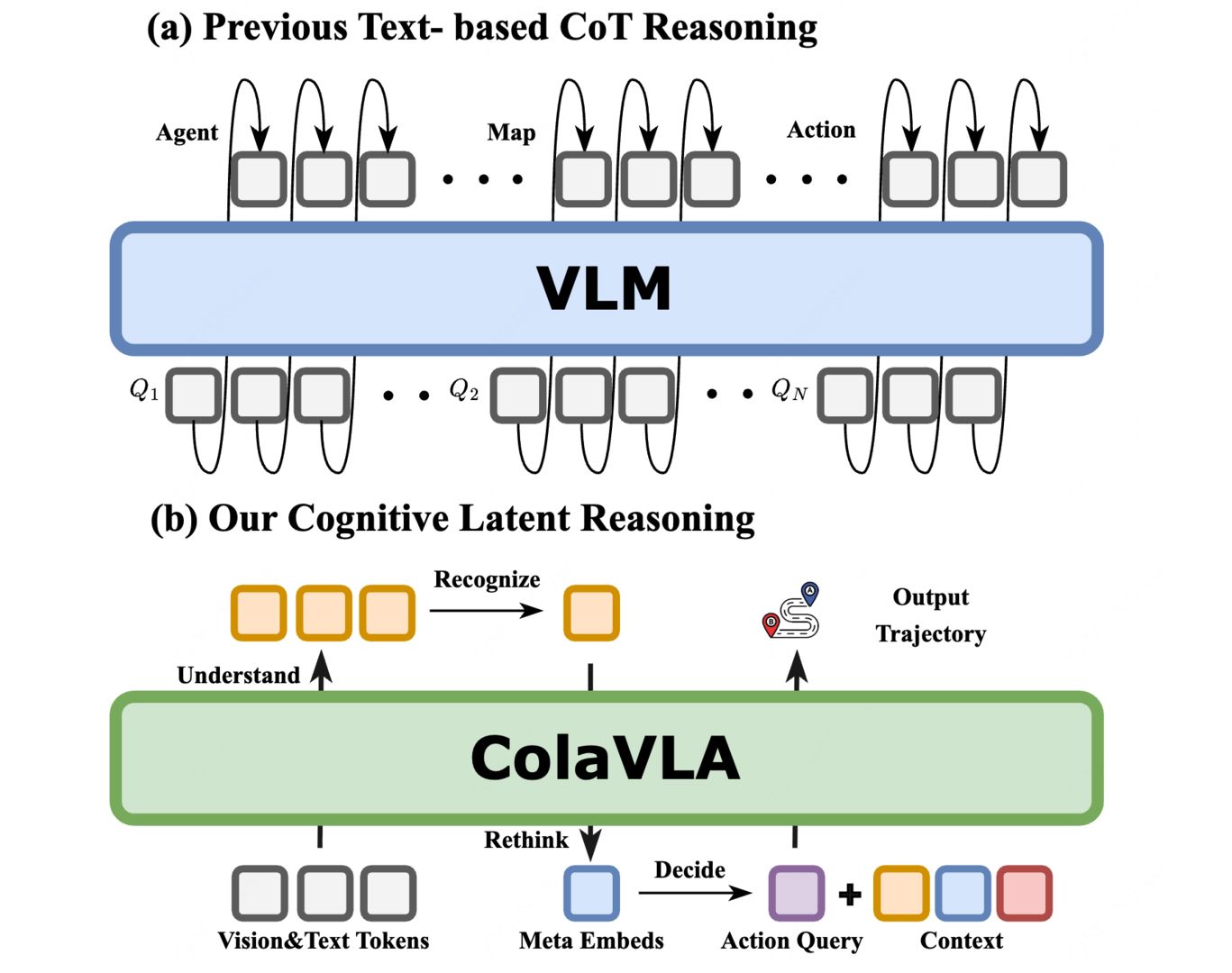
From text chain-of-thought to cognitive latent reasoning for efficient planning.
ColaVLA is a unified vision–language–action framework consisting of two core components: (1) Cognitive Latent Reasoner and (2) Hierarchical Parallel Planner. Multi-view image sequences are encoded into visual tokens (objects & maps), which are fused with an ego token and a fixed driving prompt. An ego-adaptive router selects safety-critical visual cues to form a compact pruned context. The model then performs a latent rethinking step with a bank of learnable meta-queries and finally outputs a discrete driving strategy.
Conditioned on the selected strategy, we retrieve the corresponding meta-action from an action bank and expand it into multi-scale trajectory targets via temporal embeddings and resampling. The Hierarchical Parallel Planner concatenates the pruned context and all scale-wise targets, and performs one-pass parallel decoding with a causality-preserving hybrid mask: global context aggregation to all scales, bidirectional interaction within each scale, and strictly causal information flow from coarser to finer scales. This yields efficient, causal and interpretable multi-scale trajectories.

Overall framework of ColaVLA.
We visualize representative driving scenes and the predicted trajectories to highlight how ColaVLA couples compact latent reasoning with hierarchical parallel decoding. The qualitative results demonstrate robust behavior under complex multi-agent interactions, long-horizon intent understanding, and safety-critical scenarios.
Qualitative visualization of planning results.
Open-loop (nuScenes). ColaVLA achieves strong accuracy and safety with 0.30m average L2 error and 0.23% collision rate, demonstrating precise trajectory prediction while operating efficiently in the latent action space.
Closed-loop (NeuroNCAP). ColaVLA establishes robust closed-loop driving with a 3.48 NeuroNCAP score and 36.8% collision rate under a realistic top-1 strategy setting, showing improved safety and generalization in safety-critical scenarios.
For detailed metrics, ablations, and additional analyses, please refer to the paper.

Open-loop results on nuScenes.
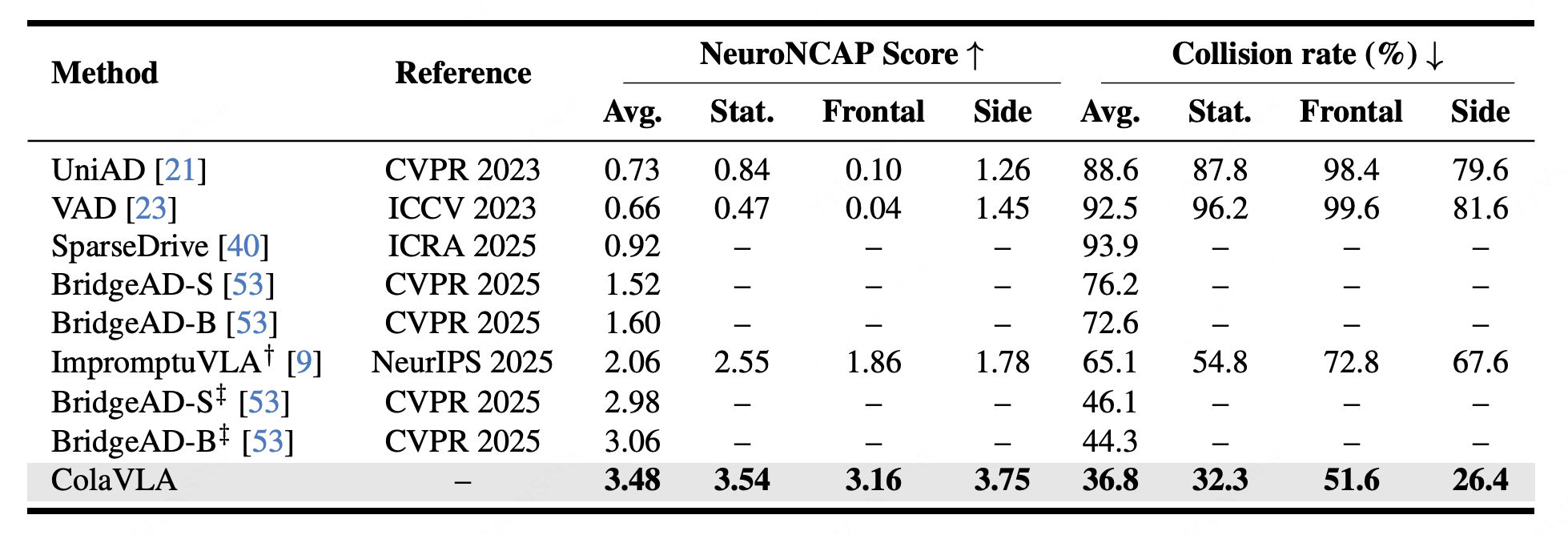
Closed-loop results on NeuroNCAP.
@misc{peng2025colavlaleveragingcognitivelatent,
title={ColaVLA: Leveraging Cognitive Latent Reasoning for Hierarchical Parallel Trajectory Planning in Autonomous Driving},
author={Qihang Peng and Xuesong Chen and Chenye Yang and Shaoshuai Shi and Hongsheng Li},
year={2025},
eprint={2512.22939},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2512.22939},
}