
visualization
Embodied intelligence requires agents to interact with 3D environments in real time based on language instructions. A foundational task in this domain is ego-centric 3D visual grounding. However, the point clouds rendered from RGB-D images retain a large amount of redundant background data and inherent noise, both of which can interfere with the manifold structure of the target regions. Existing point cloud enhancement methods often require a tedious process to improve the manifold, which is not suitable for real-time tasks. We propose Proxy Transformation suitable for multimodal task to efficiently improve the point cloud manifold. Our method first leverages Deformable Point Clustering to identify the point cloud sub-manifolds in target regions. Then, we propose a Proxy Attention module that utilizes multimodal proxies to guide point cloud transformation. Built upon Proxy Attention, we design a submanifold transformation generation module where textual information globally guides translation vectors for different submanifolds, optimizing relative spatial relationships of target regions. Simultaneously, image information guides linear transformations within each submanifold, refining the local point cloud manifold of target regions. Extensive experiments demonstrate that Proxy Transformation significantly outperforms all existing methods, achieving an impressive improvement of 7.49% on easy targets and 4.60% on hard targets, while reducing the computational overhead of attention blocks by 40.6%. These results establish a new SOTA in ego-centric 3D visual grounding, showcasing the effectiveness and robustness of our approach.
illustration
In ego-centric 3D visual grounding, we first generate a uniform grid prior in space and perform an initial clustering. Each cluster is then processed by an offset network to obtain deformable offsets for the cluster centers, allowing the initial grid prior to be shifted toward more important regions and enabling clustering to capture the sub-manifold of the target region. We utilize a proxy block based on proxy attention to process multi-modal information, obtaining a transformation matrix and translation vector for each sub-manifold. This optimizes the relative positions and internal structures of the sub-manifolds, which are subsequently fed into downstream structures for feature learning and fusion, ultimately achieving precise localization of the target object in the scene.
overall framework
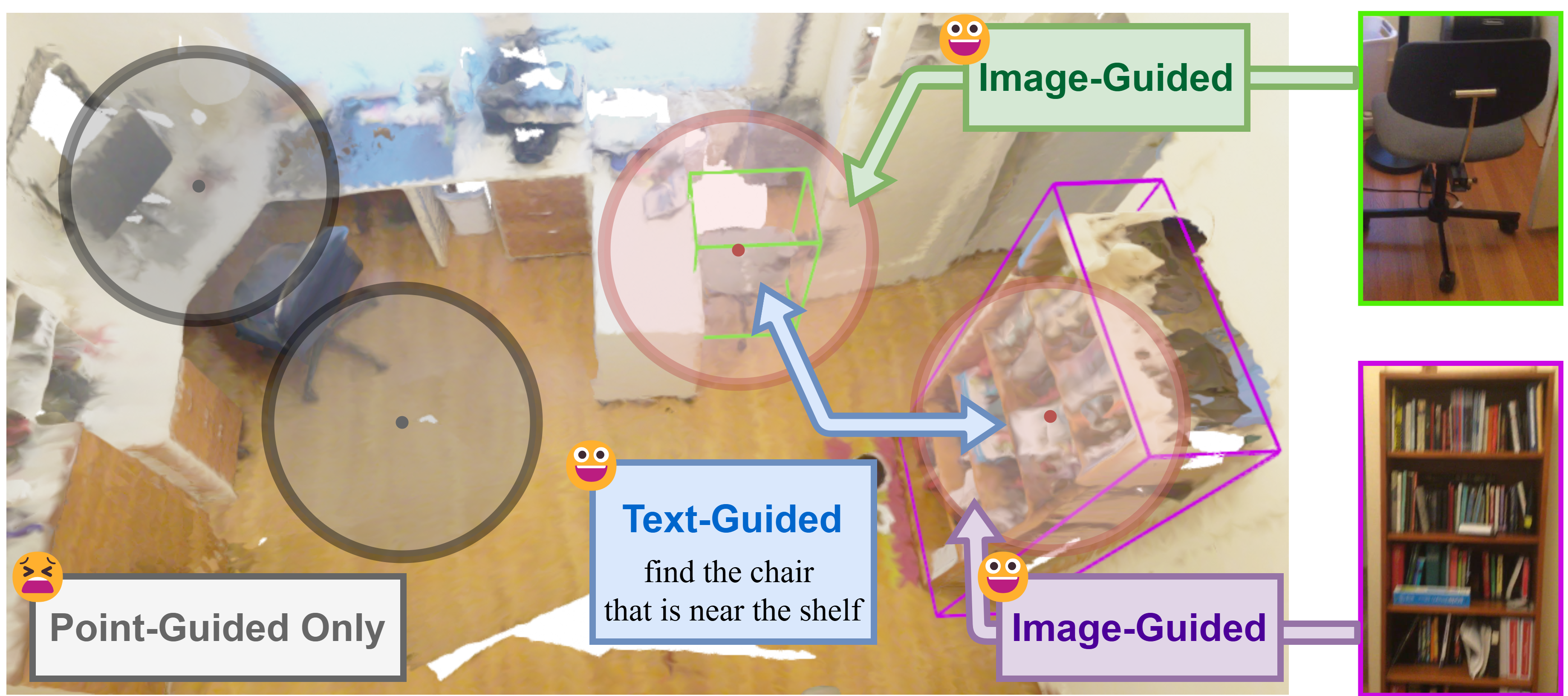
With our deformable point clustering and Proxy Transformation, the point cloud structure in target regions is optimized, providing higher-quality data for subsequent feature learning and fusion. As shown in our visualization results, reference objects in these regions are small and difficult to distinguish, but with the enhanced manifold structure, our model effectively captures the relationships between target and reference objects, achieving improved grounding performance.
visualization
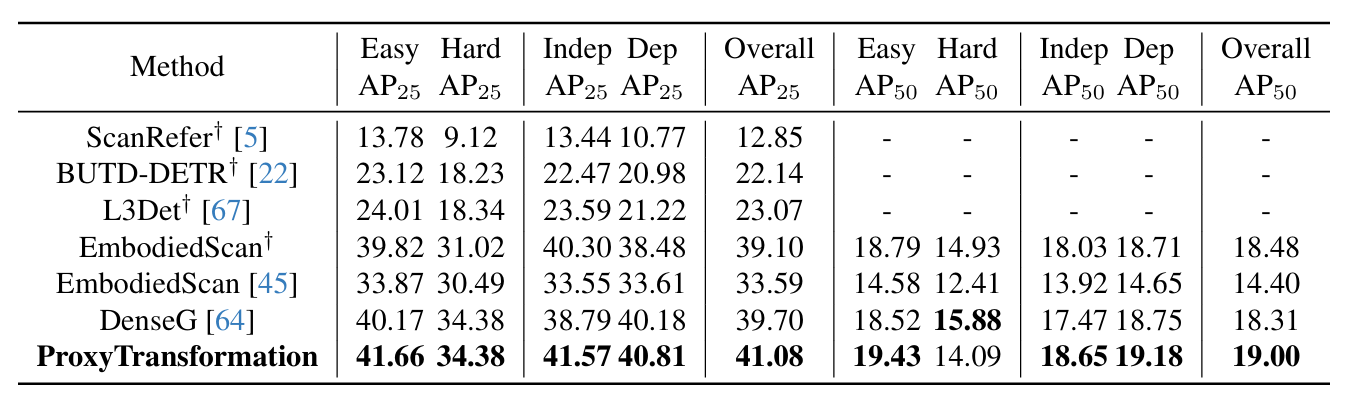
As shown in the figure below, Proxy Transformation achieves a notable 7.49% and 4.60% improvement over the previous strongest baseline, EmbodiedScan, on the Overall@0.25 and Overall@0.50.
Although only trained on the mini dataset, our method even surpasses the baseline trained on the full dataset. Through deformable point clustering, our model focuses on the most crucial target regions in the scene, reducing extra computational overhead caused by redundant point clouds and improving efficiency. Additionally, a grid prior preserves essential original spatial information, mitigating early training instability.
Recognizing that text information provides global positional relationships among different submanifolds and image information offers local semantic details within each submanifold, we designed a generalized proxy attention mechanism to guide local transformations of the selected point cloud submanifolds. These transformations optimize local point cloud structures for each submanifold, ultimately providing higher-quality data for subsequent feature extraction and fusion.
For more details on the ablation studies, please refer to the original paper.
main results
@inproceedings{peng2025proxytransformation,
title={ProxyTransformation: Preshaping Point Cloud Manifold With Proxy Attention For 3D Visual Grounding},
author={Peng, Qihang and Zheng, Henry and Huang, Gao},
booktitle={Proceedings of the Computer Vision and Pattern Recognition Conference},
pages={24582--24592},
year={2025}
}